Claude with Amazon Bedrock ってどんなコース?

「Claude with Amazon Bedrock」は、Anthropic AcademyのシリーズNo.12に位置するクラウドエンジニア・DevOps・エンタープライズ開発者向けの中〜上級コースです。AWSのマネージドAIサービスであるAmazon Bedrockを通じてClaudeを本番環境にデプロイし、安全かつスケーラブルに運用するための知識を体系的に学びます。
このコースが重要なのは、企業でClaudeを使う場合、多くのケースで「Anthropic APIを直接叩く」のではなく「AWSのBedrock経由でアクセスする」パターンが選ばれるからです。セキュリティ、コンプライアンス、課金管理、既存インフラとの統合――企業が求めるあらゆる要件を満たすには、Bedrockという「エンタープライズの器」に乗せるのが最も合理的です。
コースは約2〜3時間で修了でき、6〜8のモジュール構成。AWSアカウントでの実際のハンズオン操作も含まれるため、座学だけでなく手を動かして学べる実践的な内容になっています。
Claude with Amazon Bedrock 基本情報
URL — https://anthropic.skilljar.com/claude-in-amazon-bedrock
レベル — 中級〜上級(クラウドエンジニア / DevOps / エンタープライズ開発者向け)
所要時間 — 約2〜3時間
構成 — 6〜8モジュール + 最終アセスメント
修了証 — あり(最終アセスメント合格後)
前提知識 — AWSアカウント保有、AWSの基本操作(IAM、VPCなど)、Claude APIの基礎理解(推奨)
対象 — クラウドエンジニア、DevOps、AWS環境でAIをデプロイしたいエンタープライズ開発者

Bedrock……ベッドロック……? マインクラフトの地底にある硬いブロック……じゃないよね? AWSのサービスの名前ってこと?

正解です。Amazon BedrockはAWSが提供するフルマネージドの生成AIサービスで、Claude、Llama、Mistral、Titan、Stable Diffusionなど複数のファウンデーションモデルを1つのAPIから利用できるプラットフォームです。「Bedrock=岩盤」の名前の通り、エンタープライズAIの基盤として設計されています。

ってことは、Claudeだけじゃなくて色んなAIモデルが全部同じ場所から使えるってこと? なんか「AIのデパート」みたいだね!

良い例えです。ただし、このコースが注目するのはBedrock上のClaudeです。Bedrockの中でClaudeは最も利用されているモデルの1つであり、企業がBedrockを導入する最大の理由の1つが「Claudeを安全に使いたいから」です。
Amazon Bedrockの基本 ― マネージドAIサービスとしての位置づけ
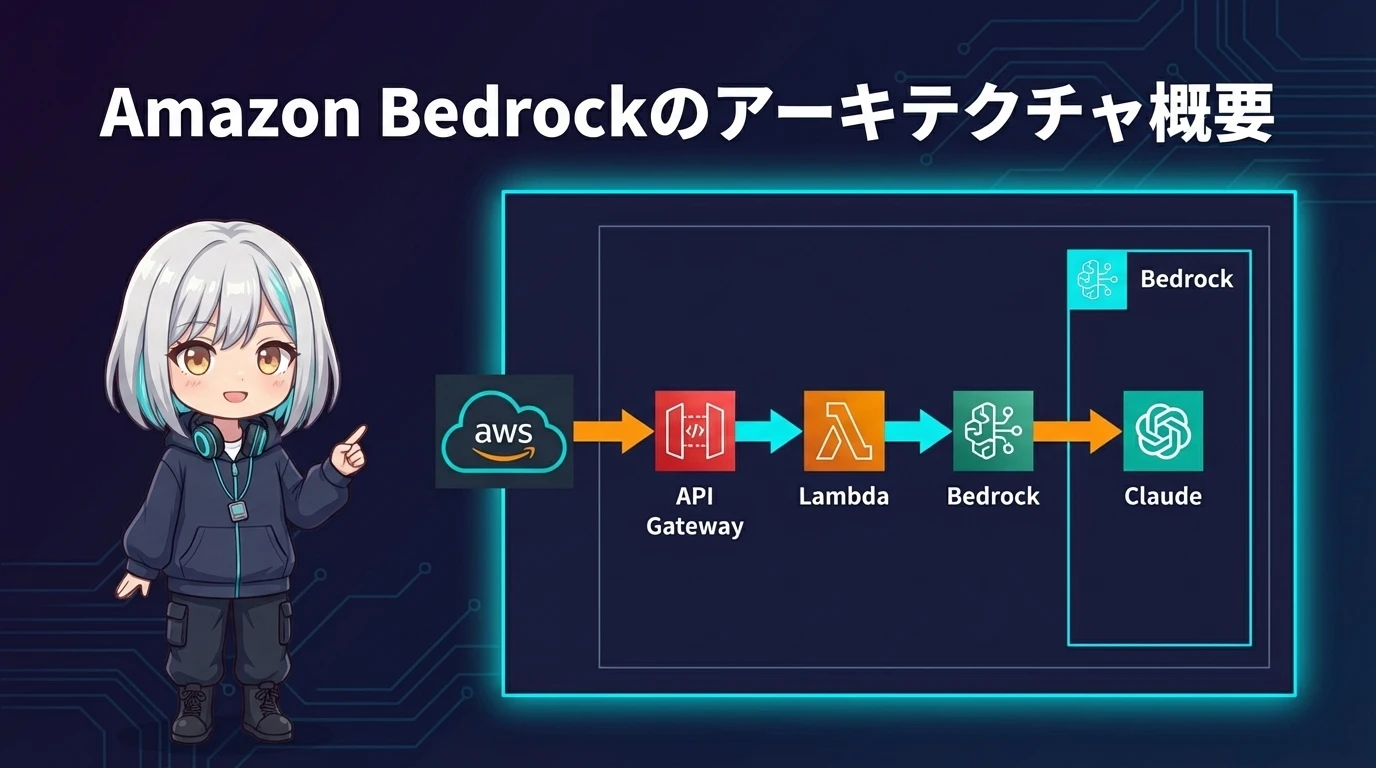
コースの最初のモジュールでは、Amazon Bedrockそのものの仕組みを学びます。Bedrockを理解するには、まず「マネージドAIサービスとは何か」を押さえる必要があります。
マネージドAIサービスとは
通常、大規模言語モデル(LLM)を本番環境で動かすには、GPUサーバーの調達、モデルのデプロイ、スケーリング、監視、セキュリティ設定……と膨大なインフラ構築が必要です。これを全部AWSが代行してくれるのが「マネージドサービス」という考え方です。
Amazon Bedrockの場合、ユーザーは以下のことを一切やる必要がありません。
- GPUサーバーの管理 ― モデルを動かすためのハードウェアはAWSが運用。ユーザーはAPIを叩くだけ
- モデルのデプロイ ― モデルのバイナリをダウンロードしたりコンテナに詰めたりする必要なし。コンソールでモデルを有効化すれば即使える
- スケーリング ― リクエストが増えても自動的にスケール。1リクエスト/分でも10万リクエスト/分でもBedrock側が対応
- パッチ適用・アップデート ― Claudeの新バージョンが出たらBedrock側でモデルが更新される。インフラ再構築は不要

要するに「面倒なインフラ全部AWSがやるから、開発者はAIの使い方に集中してね」ってサービスか。Anthropic APIを直接使うのとは何が違うの?

核心的な質問です。Anthropic APIを直接使う場合もサーバーレスで楽ですが、BedrockにはAWSのエコシステム全体との統合という決定的な違いがあります。IAMによるアクセス制御、VPCによるネットワーク分離、CloudTrailによる監査ログ、CloudWatchによるメトリクス監視――これらがすべてAWSネイティブに統合されるのです。次のセクションで詳しく比較しましょう。
Bedrockのアーキテクチャ概要
Bedrockのアーキテクチャは以下のレイヤーで構成されています。
- Model Layer ― ファウンデーションモデル(Claude、Llama等)が動作するレイヤー。ユーザーからは見えない
- API Layer ― InvokeModel、InvokeModelWithResponseStream等のBedrock APIエンドポイント
- Security Layer ― IAMポリシー、VPCエンドポイント、KMS暗号化による保護
- Feature Layer ― Guardrails、Knowledge Bases、Agents等のBedrock固有機能
- Observability Layer ― CloudWatch Logs、CloudTrail、Model Invocation Loggingによる可観測性
Bedrockで利用可能な主要Claudeモデル(2026年4月時点)
Claude Opus 4 — 最高品質。複雑な推論・分析・コード生成に最適
Claude Sonnet 4 — バランス型。コスト効率と品質の両立。最も汎用的
Claude Haiku 3.5 — 超高速・低コスト。分類・要約・軽量タスク向け
モデルID例 — anthropic.claude-sonnet-4-20250514-v1:0
注意 — モデルは手動で有効化が必要(デフォルトでは使えない)
なぜBedrock経由でClaudeを使うのか ― 直接API vs Bedrock の徹底比較

このセクションはコースの中でも特に重要なパートです。「Anthropic APIを直接使えばいいのでは?」という疑問に、コースは明確に答えを出します。結論から言えば、エンタープライズ環境では圧倒的にBedrockが有利ですが、ユースケースによっては直接APIの方が適切な場合もあります。
比較1: セキュリティとアクセス制御
直接Anthropic APIの場合、APIキーの管理は開発者の責任です。キーが漏洩すれば不正利用される可能性があり、きめ細かなアクセス制御(「このユーザーにはSonnetのみ許可、Opusは禁止」など)を実装するには自前のミドルウェアが必要になります。
Bedrock経由の場合、AWSのIAM(Identity and Access Management)がそのまま使えます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-sonnet-4-*"
},
{
"Effect": "Deny",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-opus-4-*"
}
]
}このIAMポリシーの例では、「Claude Sonnetの呼び出しは許可するが、Claude Opusの呼び出しは拒否する」というアクセス制御を宣言しています。APIキーを個別に管理する必要はなく、AWSの既存のユーザー・ロール管理の仕組みがそのまま使えるのです。

なるほど……! APIキーを1個渡して「はいどうぞ」じゃなくて、「誰が何のモデルをどの条件で使えるか」を細かく設定できるのか。企業だと「新人はHaikuだけ、シニアはOpusもOK」みたいな制御が必要なんだろうね。
その通りです。さらにIAMにはConditionキーがあり、「特定のVPCからのアクセスのみ許可」「特定のタグが付いたリソースからのみ許可」など、非常にきめ細かい制御が可能です。エンタープライズのセキュリティチームが求める要件の大半はIAMで実現できます。
比較2: ネットワークセキュリティ
Anthropic APIを直接呼ぶ場合、トラフィックはインターネットを経由します。企業によっては「社内データをインターネットに出すのはNG」というポリシーがあり、これが直接APIの利用を阻むことがあります。
BedrockではVPCエンドポイント(AWS PrivateLink)を使うことで、トラフィックがAWSネットワーク内に閉じた経路を通ります。インターネットに一切出ることなくClaudeを呼び出せるため、金融機関や医療機関など厳格なネットワークポリシーを持つ組織でも導入できます。
比較3: 監査ログとコンプライアンス
エンタープライズでは「誰が、いつ、どのモデルを、何の目的で使ったか」を記録する監査ログが必須です。BedrockではAWS CloudTrailが全APIコールを自動的に記録し、Model Invocation Loggingで入出力の内容まで保存できます(オプション)。
これにより、SOC 2、HIPAA、GDPRなどのコンプライアンス要件への対応が格段に楽になります。「AIの利用履歴を監査可能な形で保持する」という要件を、追加開発なしで満たせるのです。
比較4: 支払い一元化
企業のIT部門にとって「新しいベンダーとの契約」はそれだけで大きなハードルです。Bedrock経由であればClaude の利用料金はAWSの請求書に統合されます。既にAWSと契約がある企業なら、新しい契約手続きや購買稟議なしでClaudeを使い始められます。

あー! 企業だと「新しいサービスの契約」って購買部門の承認が必要だったりするんだよね! でもAWSならもう契約済みだから、「AWSの使い方を増やすだけ」で通せる! これは企業のIT部門にとっては超でかいメリットだ!
比較5: まとめ表
| 観点 | 直接Anthropic API | Amazon Bedrock経由 |
|---|---|---|
| 認証 | APIキー | IAMロール / 一時認証情報 |
| アクセス制御 | APIキー単位(粗い) | IAMポリシー(非常にきめ細かい) |
| ネットワーク | インターネット経由 | VPC PrivateLink対応 |
| 監査ログ | 自前で実装 | CloudTrail自動記録 |
| 課金 | Anthropicに直接支払い | AWS請求書に統合 |
| 追加機能 | なし(APIのみ) | Guardrails, Knowledge Bases, Agents |
| 最新モデル | 即日利用可能 | 数日〜数週間の遅延あり |
| セットアップ | APIキー取得のみ(簡単) | IAM, モデル有効化等(やや手間) |
| 適用場面 | 個人開発、PoC、スタートアップ | エンタープライズ、規制業種、大規模運用 |

補足すると、「最新モデルへのアクセス速度」は直接APIの方が有利です。Anthropicが新モデルをリリースしてからBedrockに反映されるまで数日〜数週間のタイムラグがあります。最新モデルを即座に試したいPoCフェーズでは直接API、本番環境に載せるならBedrockという使い分けが一般的です。
学べる内容 ― 各モジュール詳細
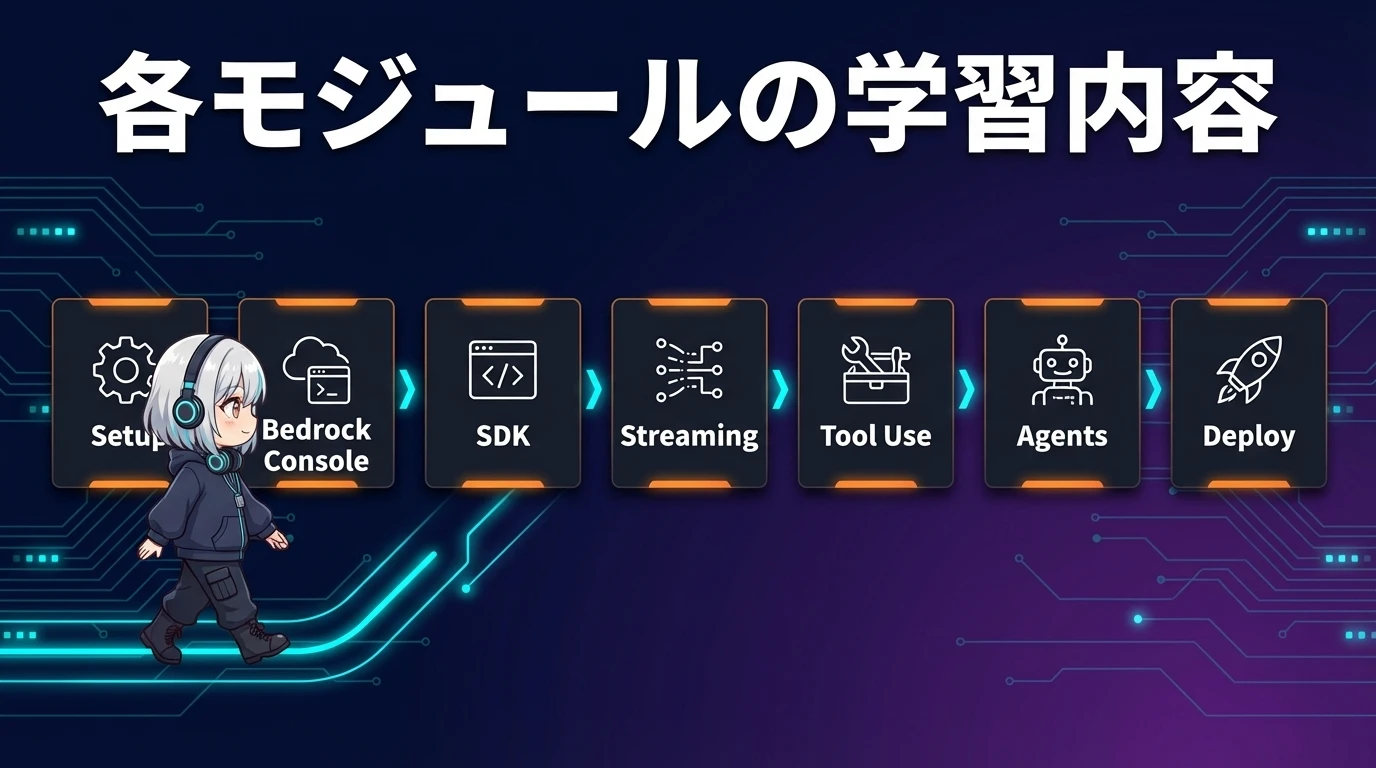
ここからはコースの各モジュールで学ぶ内容を、実際のコード例を交えながら詳しく解説します。
モジュール1: Bedrockでのモデル有効化手順
Bedrockではモデルはデフォルトで無効になっています。Claudeを使い始めるには、AWSマネジメントコンソールから明示的にモデルアクセスをリクエストする必要があります。
手順は以下の通りです。
- AWSマネジメントコンソールにログイン
- Amazon Bedrockコンソールを開く
- 左メニューから「Model access(モデルアクセス)」を選択
- Anthropicセクションから使いたいClaudeモデルにチェックを入れる
- 「Request model access(モデルアクセスをリクエスト)」をクリック
- 利用規約に同意して送信
- 数分以内にアクセスが有効化される(Anthropicモデルの場合、通常は自動承認)

えっ、デフォルトで使えないの!? 「有効化」を忘れてて「動かない!」ってパニックになる人いそうだね。

実際に非常に多い「Bedrock初心者あるある」の第1位です。AccessDeniedExceptionが出たらまずモデルアクセスの有効化を確認してください。もう1つの注意点として、リージョンごとに有効化が必要です。us-east-1で有効化しても、ap-northeast-1(東京)では別途有効化が必要です。
モジュール2: Bedrock APIの使い方(boto3での呼び出し)
Bedrockでは、AWSの公式SDK(PythonならBoto3)を使ってClaudeを呼び出します。Anthropic直接APIとはリクエスト形式が異なる点がコースの重要ポイントです。
まず、最もシンプルな呼び出しコードを見てみましょう。
import boto3
import json
# Bedrock Runtimeクライアントを作成
client = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
# リクエストボディを構築(Anthropic Messages API形式)
request_body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Amazon Bedrockとは何ですか?日本語で簡潔に説明してください。"
}
]
})
# モデルを呼び出す
response = client.invoke_model(
modelId="anthropic.claude-sonnet-4-20250514-v1:0",
contentType="application/json",
accept="application/json",
body=request_body
)
# レスポンスを解析
response_body = json.loads(response["body"].read())
print(response_body["content"][0]["text"])注目すべきポイントがいくつかあります。
- 認証がAPIキーではない ― boto3はAWSの認証情報(~/.aws/credentials、環境変数、IAMロール等)を自動的に使う。APIキーをコードに書く必要がない
anthropic_versionフィールド ― Bedrock上のClaude APIバージョンを指定する。直接APIにはないBedrock固有のフィールドmodelIdの形式 ―anthropic.claude-sonnet-4-20250514-v1:0のようにBedrock固有のモデルID形式を使う(直接APIのclaude-sonnet-4-20250514とは異なる)- サービス名が
bedrock-runtime― モデル呼び出しにはbedrock-runtimeを使う(bedrockはモデル管理用で別のサービス)

コードの雰囲気は直接APIと似てるけど、微妙に違うところがたくさんあるんだね。特に認証が「AWSの仕組み」になるのが大きな違いか……。APIキーをコードに書かなくていいのはセキュリティ的にかなり良いね!
次に、ストリーミングレスポンス(回答を少しずつリアルタイムで受け取る)のコード例です。チャットアプリのようにリアルタイム表示したい場合に使います。
import boto3
import json
client = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
request_body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": "Bedrockを使う3つのメリットを教えて"
}
]
})
# ストリーミングで呼び出し
response = client.invoke_model_with_response_stream(
modelId="anthropic.claude-sonnet-4-20250514-v1:0",
contentType="application/json",
accept="application/json",
body=request_body
)
# ストリームからチャンクを逐次読み取り
for event in response["body"]:
chunk = json.loads(event["chunk"]["bytes"])
if chunk["type"] == "content_block_delta":
print(chunk["delta"]["text"], end="", flush=True)
print() # 最終改行Bedrock API vs 直接Anthropic APIの主な差分
認証 — 直接API: x-api-keyヘッダー → Bedrock: AWS SigV4署名(SDKが自動処理)
エンドポイント — 直接API: api.anthropic.com → Bedrock: bedrock-runtime.{region}.amazonaws.com
モデル指定 — 直接API: model: "claude-sonnet-4-20250514" → Bedrock: modelId: "anthropic.claude-sonnet-4-20250514-v1:0"
バージョン — 直接API: anthropic-versionヘッダー → Bedrock: リクエストボディ内のanthropic_version
ストリーミング — 直接API: SSE形式 → Bedrock: EventStream形式(invoke_model_with_response_stream)
モジュール3: IAMポリシー設定 ― 最小権限の原則を実現する
コースの中盤で重点的に扱われるのがIAMによるアクセス制御です。AWSの「最小権限の原則(Principle of Least Privilege)」をBedrock環境に適用する方法を学びます。
以下は、本番環境で推奨されるIAMポリシーの例です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowClaudeSonnetInvocation",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-sonnet-4-*"
],
"Condition": {
"StringEquals": {
"aws:RequestedRegion": "us-east-1"
}
}
},
{
"Sid": "AllowBedrockGuardrails",
"Effect": "Allow",
"Action": [
"bedrock:ApplyGuardrail"
],
"Resource": "arn:aws:bedrock:us-east-1:123456789012:guardrail/*"
},
{
"Sid": "DenyHighCostModels",
"Effect": "Deny",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-opus-4-*"
]
}
]
}このポリシーでは、以下の3つのルールを定義しています。
- Claude Sonnetの呼び出しを許可(ストリーミング含む、us-east-1リージョン限定)
- Guardrailsの適用を許可(後述するAIの安全性制御機能)
- Claude Opusの呼び出しを明示的に拒否(コスト制御のため)

すごい……! 「このモデルだけ使える」「このリージョンだけ」「Opusは使わせない」って全部JSONで宣言するだけで制御できるんだ。これはセキュリティチームが好きそう。
IAMの強力さは「宣言的であること」にあります。「やっていいこと」と「やってはいけないこと」をJSONで書くだけで、AWSが強制的にそのルールを適用する。コード側で認可チェックを実装する必要がない。コースではLambda関数にIAMロールをアタッチして、サーバーレスでBedrockを呼ぶパターンも紹介されます。
モジュール4: Guardrails ― AIの出力を安全にコントロールする
GuardrailsはBedrock固有の最も重要な機能の1つです。Claudeの入出力に対して、企業が定めたポリシーに基づくフィルタリングを適用できます。直接Anthropic APIにはない、Bedrockならではの機能です。
Guardrailsでできることは以下の通りです。
- コンテンツフィルタリング ― 暴力、ヘイトスピーチ、性的コンテンツなどのカテゴリごとにフィルタ強度を設定。「自社のカスタマーサポートBotでは性的なコンテンツを完全ブロック」といった制御が可能
- トピック制限 ― 「政治的な話題には回答しない」「競合製品の推薦をしない」など、特定のトピックへの回答を制限
- ワードフィルター ― 特定の単語やフレーズを含む入出力をブロック。自社の機密用語や不適切な表現のフィルタリング
- PII(個人識別情報)検出 ― メールアドレス、電話番号、クレジットカード番号などの個人情報を自動検出し、マスキングまたはブロック
- Contextual Grounding Check ― RAG(後述するKnowledge Bases)と組み合わせて、回答がソースドキュメントに基づいているかチェック。ハルシネーション(AIの作り話)を検出
import boto3
import json
client = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
# Guardrailを適用してモデルを呼び出す
request_body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "競合のA社の製品について教えてください"
}
]
})
response = client.invoke_model(
modelId="anthropic.claude-sonnet-4-20250514-v1:0",
contentType="application/json",
accept="application/json",
body=request_body,
guardrailIdentifier="my-guardrail-id", # GuardrailのID
guardrailVersion="1" # Guardrailのバージョン
)
response_body = json.loads(response["body"].read())
# Guardrailがトリガーされた場合の処理
if response_body.get("amazon-bedrock-guardrailAction") == "GUARDRAIL_INTERVENED":
print("Guardrailにより回答がブロックされました")
print(response_body["content"][0]["text"]) # Guardrailの代替メッセージ
else:
print(response_body["content"][0]["text"])
おおお! 「競合のことは話さない」ってルールをAIに強制できるんだ! これはカスタマーサポートBotとかで超重要だね。うっかり「A社の製品の方がいいですよ」とか言っちゃうAIがいたら大問題だもん!
重要なのは、Guardrailsがモデルとは独立したレイヤーとして機能する点です。Claudeのシステムプロンプトに「競合のことは話すな」と書くだけでは、プロンプトインジェクションで突破される可能性がある。Guardrailsはモデルの外側で動作するため、より堅牢です。コースではGuardrailsの作成・テスト・運用の全プロセスを学びます。
モジュール5: Knowledge Bases ― RAGで社内知識を活用する
Knowledge Basesは、企業の独自データをClaudeの回答に反映させるRAG(Retrieval-Augmented Generation)システムをフルマネージドで構築する機能です。
RAGの仕組みを簡潔に言えば、「ユーザーの質問に関連する社内ドキュメントをベクトル検索で見つけ出し、その内容をClaudeに渡して回答を生成させる」というものです。これにより、Claudeの学習データにはない自社固有の情報(製品マニュアル、社内規定、FAQ等)に基づいた回答が得られます。
Knowledge Basesの構成要素は以下の通りです。
- データソース ― S3バケットにドキュメント(PDF、HTML、テキスト等)をアップロード。Confluence、SharePoint、Salesforceなどのコネクタも利用可能
- Embedding Model ― ドキュメントをベクトル化するモデル。Amazon Titan EmbeddingsやCohere Embedが選択可能
- Vector Store ― ベクトル化されたデータを保存・検索するデータベース。Amazon OpenSearch Serverless、Pinecone、Redisなどが利用可能
- Retrieval & Generation ― 質問に関連するドキュメントを検索し、Claudeに渡して回答を生成
import boto3
import json
# Bedrock Agent Runtimeクライアント(Knowledge Basesの検索に使う)
agent_client = boto3.client(
service_name="bedrock-agent-runtime",
region_name="us-east-1"
)
# Knowledge Baseに対して質問する
response = agent_client.retrieve_and_generate(
input={
"text": "製品Xの返品ポリシーを教えてください"
},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB12345678",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-sonnet-4-20250514-v1:0",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5 # 上位5件のドキュメントを取得
}
}
}
}
)
# 回答を表示
print(response["output"]["text"])
# 参照元ドキュメントを表示
for citation in response["citations"]:
for ref in citation["retrievedReferences"]:
print(f"出典: {ref['location']['s3Location']['uri']}")
print(f"抜粋: {ref['content']['text'][:200]}...")
print("---")Knowledge Basesの最大のメリットは、「出典の明示」が自動で行われる点です。回答にどのドキュメントのどの部分が使われたかが分かる。これは企業利用では必須の要件で、「AIが勝手に作り話をしていないか」を確認できる証拠になります。Guardrailsと組み合わせれば、出典に基づかない回答をブロックすることも可能です。

「出典付き」って、学校のレポートで「参考文献」を載せるみたいだね! AIの回答が信頼できるかどうか、元のドキュメントに戻って確認できるのは安心感がある!
モジュール6: Bedrock Agents ― AIに自律的なタスク実行をさせる
Bedrock Agentsは、Claudeに外部ツールの呼び出しやマルチステップのタスク実行を行わせる機能です。単に質問に答えるだけでなく、「データベースを検索して、結果を整理して、メールで送信する」といった一連の処理をClaudeが自律的に計画・実行します。
Agentsの仕組みは以下の通りです。
- Instructions ― AgentにどのようなAIアシスタントとして振る舞うかを指示する(システムプロンプトに相当)
- Action Groups ― Agentが呼び出せるツール(Lambda関数やAPI)を定義する。OpenAPIスキーマで定義
- Knowledge Bases ― 前述のKnowledge Basesを接続して、社内知識も参照可能に
- Orchestration ― Claudeがユーザーの要求を分析し、必要なツールを選び、順序を決めて実行する
例えば、「カスタマーサポートAgent」を構築する場合、以下のようなAction Groupsを定義できます。
searchOrders― 注文データベースを検索するgetOrderStatus― 注文のステータスを取得するinitiateRefund― 返金処理を開始するsendEmail― 確認メールを送信する
ユーザーが「注文ID 12345のステータスを教えて。もしキャンセルされていたら返金処理をして」と言えば、Agentは自動的にgetOrderStatusで状態を確認し、キャンセル済みならinitiateRefundを呼び、sendEmailで確認メールを送る――という一連のフローを自律的に実行します。
これはもう「チャットBot」の次元を超えてるね! AIが実際にシステムを操作して仕事してくれるんだ! カスタマーサポートの自動化とか、このAgentsで一気に実現できそう!
注意点として、Agentsは強力ですが「何でもできるわけではない」です。コースではGuardrailsとの併用が強く推奨されています。Agentが「返金処理」のような金銭に関わる操作を行う場合、必ず人間の承認ステップを挟むか、金額の上限をGuardrailsで設定するなどの安全策が必要です。
モジュール7: Provisioned Throughput ― スループット保証と料金最適化
Bedrockのデフォルトの課金方式はオンデマンド(従量課金)です。リクエストごとに入力トークン数と出力トークン数に基づいて課金されます。個人開発やPoCではこれで十分ですが、大規模なエンタープライズ運用ではProvisioned Throughput(プロビジョンドスループット)の検討が必要になります。
Provisioned Throughputでは、一定量のモデル処理能力を事前に確保(予約)します。メリットは以下の通りです。
- 安定したレイテンシ ― 他のユーザーのリクエストに影響されない。常に一定の応答速度が保証される
- スループットの保証 ― 「1分あたりX万トークン」を確実に処理できる。トラフィックのピーク時にもスロットリング(速度制限)が発生しない
- コスト予測可能性 ― 月額固定費用になるため、予算計画が立てやすい
- 大量処理時のコスト効率 ― 一定量以上のリクエストがある場合、オンデマンドよりも単価が安くなる
Bedrock料金体系の整理(Claudeモデル)
オンデマンド — 入力トークン単価 + 出力トークン単価 の従量課金。初期費用ゼロ。少量利用やPoCに最適
Provisioned Throughput — Model Unit(処理能力の単位)を時間単位で予約。月額固定。大規模運用に最適
バッチ推論 — 大量のリクエストをまとめて非同期処理。オンデマンドより50%割引。レイテンシ不要のバッチ処理向け
コスト最適化のコツ — PoCはオンデマンド → 本番はProvisioned or バッチの使い分けが基本

バッチ推論で50%割引はでかい! リアルタイムで返事が必要ないケース、例えば「夜中にまとめて1000件のドキュメントを要約する」みたいな用途ならバッチ推論が圧倒的にお得ってことだよね。
正確です。コースではこの料金最適化についても具体的な試算方法を学びます。例えば「月間100万トークン処理するならオンデマンド vs Provisioned Throughputでどちらが安いか」をExcelやスプレッドシートで計算するハンズオンがあります。クラウドエンジニアにとって、コスト見積もりは上長への稟議で必ず求められるスキルです。
モジュール8: エンタープライズデプロイパターン
コースの最後のモジュールでは、実際の本番環境アーキテクチャのパターンが紹介されます。代表的な3つのパターンを解説します。
パターン1: サーバーレスアーキテクチャ(Lambda + API Gateway + Bedrock)
最もシンプルで推奨されるパターンです。ユーザーのリクエストをAPI Gateway → Lambda → Bedrock Runtimeの流れで処理します。サーバー管理が不要で、自動スケーリング。小〜中規模のアプリケーションに最適です。
import boto3
import json
import os
# Lambda関数: API GatewayからのリクエストをBedrockに中継
def lambda_handler(event, context):
client = boto3.client("bedrock-runtime", region_name="us-east-1")
# リクエストボディからユーザーのメッセージを取得
body = json.loads(event["body"])
user_message = body["message"]
request_body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"system": "あなたは親切なカスタマーサポート担当者です。日本語で回答してください。",
"messages": [
{"role": "user", "content": user_message}
]
})
response = client.invoke_model(
modelId="anthropic.claude-sonnet-4-20250514-v1:0",
contentType="application/json",
accept="application/json",
body=request_body,
guardrailIdentifier=os.environ["GUARDRAIL_ID"],
guardrailVersion=os.environ["GUARDRAIL_VERSION"]
)
response_body = json.loads(response["body"].read())
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({
"response": response_body["content"][0]["text"]
}, ensure_ascii=False)
}パターン2: コンテナアーキテクチャ(ECS / EKS + Bedrock)
より複雑なアプリケーション、例えばWebSocketによるリアルタイムチャット、セッション管理、マルチターン会話の状態保持などが必要な場合は、ECS(Elastic Container Service)やEKS(Elastic Kubernetes Service)上のコンテナからBedrockを呼び出すパターンが使われます。
パターン3: マルチアカウント / マルチリージョン構成
大企業では、開発環境・ステージング環境・本番環境をAWSの別アカウントで分離するのが一般的です。各アカウントからクロスアカウントIAMロールでBedrockを呼び出す構成や、障害対策として複数リージョンに分散するパターンも紹介されます。

マルチアカウント・マルチリージョン……スケールがでかすぎて頭がクラクラしてきた……。でも大企業ってそういうレベルで設計するんだね……。
安心してください。コースでは最初にパターン1(サーバーレス)をハンズオンで構築し、そこからスケールアップする場合の選択肢としてパターン2、3が紹介されるという流れです。まずはパターン1を理解すれば十分実用的です。
直接API vs Bedrock ― どちらを選ぶべきか判断基準
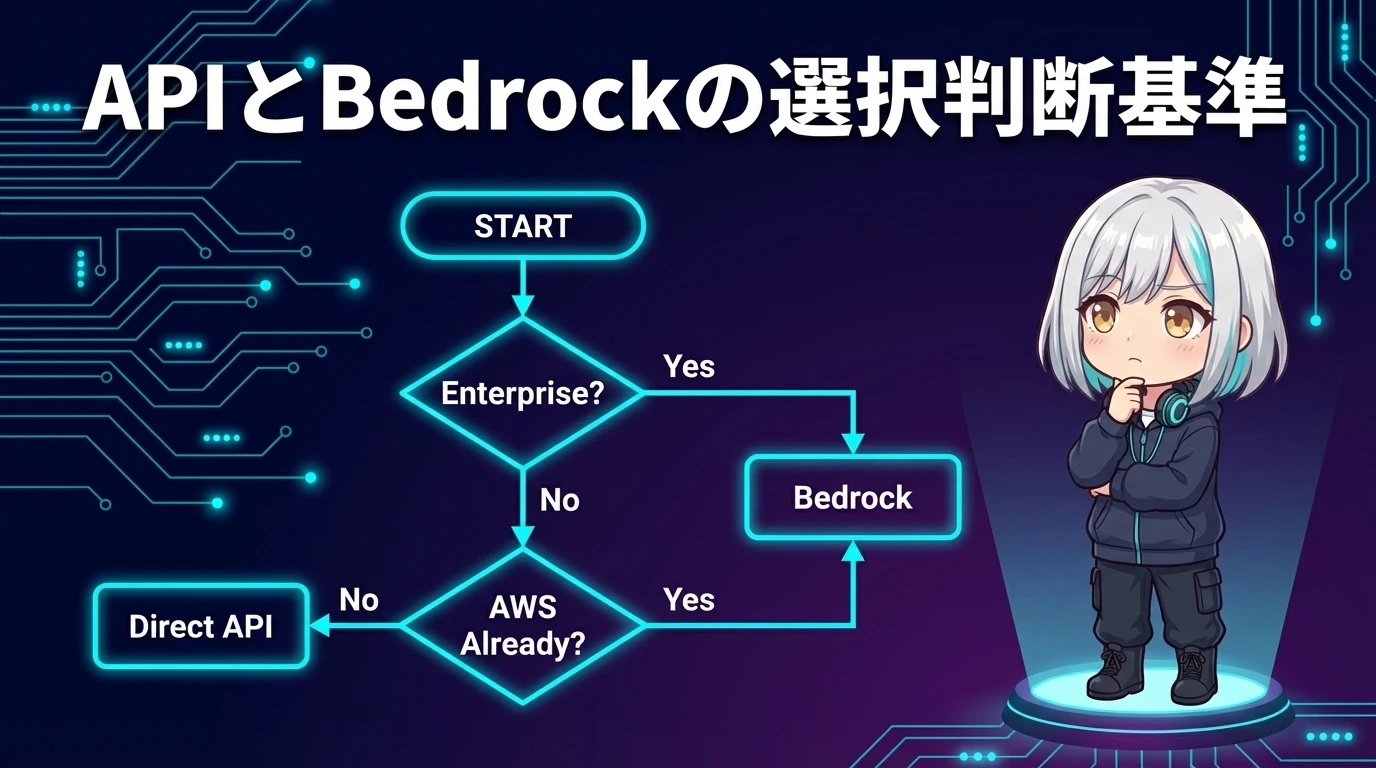
コースの終盤では、「結局どっちを使えばいいの?」という最も実用的な判断基準が提示されます。以下のフローチャートで判断できます。
直接Anthropic APIを選ぶべきケース
- 個人開発や小規模プロジェクト ― AWSアカウントを持っていない、IAMの設定が面倒、すぐに始めたい場合
- 最新モデルを即座に使いたい ― Anthropicが新モデルをリリースした直後に試したい場合。Bedrockへの反映には数日〜数週間かかる
- Anthropic固有機能(MCP等)を使いたい ― Model Context Protocol(MCP)など、Anthropic直接APIでのみ利用可能な最新機能がある場合
- PoC(概念実証)フェーズ ― とにかく素早くプロトタイプを作りたい場合。セットアップが最も簡単
Amazon Bedrockを選ぶべきケース
- 企業のコンプライアンス要件がある ― SOC 2、HIPAA、GDPRなどの認証が必要な場合。Bedrock + AWS環境で対応可能
- 既存のAWSインフラがある ― 既にAWSを使っている企業で、IAM、VPC、CloudTrail等の既存基盤と統合したい場合
- 複数のAIモデルを使い分けたい ― Claude + Llama + Stable Diffusionなど、複数モデルを1つのプラットフォームから管理したい場合
- RAGやAgentsを使いたい ― Knowledge BasesやAgentsのようなマネージド機能が必要な場合
- 課金をAWSに統合したい ― 新しいベンダー契約を避けたい、AWSの請求書に一元化したい場合
- 大規模な本番運用 ― スループット保証、監査ログ、きめ細かなアクセス制御が必要な場合

なるほど! 要するに「個人・小規模・PoC → 直接API」「企業・大規模・本番 → Bedrock」って大まかに覚えておけばいいんだね!
良いまとめです。実際の現場では「PoCは直接APIで素早く作り、承認が取れたらBedrock環境に移行する」というパターンが非常に多いです。コースではこの移行パターン(APIのリクエスト形式の変換、IAMの設定方法等)も詳しく扱われます。
受講のコツ ― AWSの無料利用枠を活用して実際に試す

このコースを最大限に活用するためのコツをまとめます。
コツ1: AWSアカウントを事前に準備する
コースにはハンズオン要素が含まれています。AWSアカウントがないと座学だけの受講になってしまうため、事前にアカウントを作成しておきましょう。AWSアカウントの作成自体は無料です。ただし、Bedrockの利用には課金が発生する点に注意してください。
コツ2: AWS Free Tier(無料利用枠)を活用する
AWSには新規アカウント向けの無料利用枠があります。Bedrockも一部モデルで無料利用枠が提供されることがあります。コースの簡単なハンズオンであれば、数ドル〜数十ドル以内に収まることが多いですが、必ず利用後にBilling(請求)ダッシュボードで金額を確認する習慣をつけてください。
コツ3: CloudShellを活用する
AWSマネジメントコンソールにはCloudShell(ブラウザ内ターミナル)が備わっています。ローカルにPython環境を構築しなくても、CloudShellからboto3を使ったBedrock APIの呼び出しを即座に試せます。セットアップの手間を省きたい場合に便利です。
コツ4: 直接APIでの経験があると理解が早い
このコースの前提として「Claude APIの基礎理解」が推奨されています。先にAnthropicの直接APIでClaude を使った経験があると、「Bedrockでは何が違うのか」が明確に分かり、学習効率が大幅に上がります。まだの場合は「Real World Prompting」コースや「Building with the Claude API」コースを先に受けるのも良い選択です。

CloudShellいいね! 「ローカルに環境構築するのが面倒で手が動かない」パターンって多いから、ブラウザだけで試せるのは助かる! あと、お金のことは本当に大事……AWSは知らない間に課金されることがあるから、Billingダッシュボードの確認は絶対やろうね!
ハンズオン前の準備チェックリスト
AWSアカウント — 作成済みか確認。MFAの有効化も推奨
IAMユーザー — ルートアカウントではなくIAMユーザーで作業する(AWSのベストプラクティス)
リージョン — us-east-1(バージニア北部)を推奨(Claudeモデルが最も早く利用可能)
モデルアクセス — BedrockコンソールでClaude モデルへのアクセスを事前に有効化
Billing Alert — 予算アラートを設定して想定外の課金を防ぐ
次に進むコース ― Vertex AIとの対比、そしてその先へ
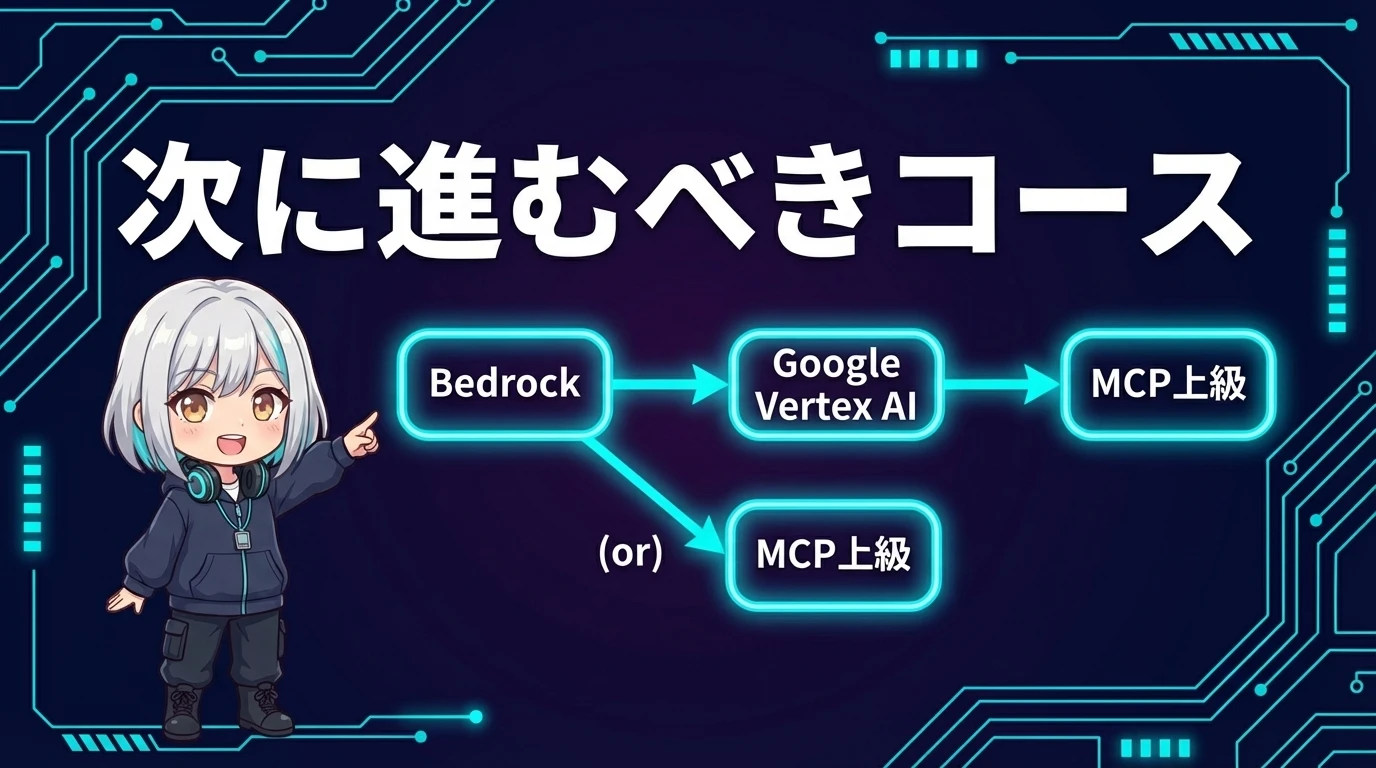
Claude with Amazon Bedrockを修了したら、次は以下のコースが自然な学習パスです。
- Google CloudでClaudeを使いたい → Claude with Google Cloud Vertex AI(Bedrockと同じコンセプトのGoogle Cloud版。比較することで「クラウドプロバイダーに依存しない設計」の理解が深まる)
- Claude APIの詳細を学びたい → Building with the Claude API(直接APIの詳細。Bedrockとの差分を理解した上で学ぶと理解が深い)
- プロンプトエンジニアリングを極めたい → Prompt Engineering Interactive Tutorial(Bedrockで使うプロンプトの品質を上げる)
- セキュリティに特化して学びたい → Admin Console & Security(組織全体のClaude利用ガバナンス)

BedrockとVertex AIの両方を学べば、「AWS派」と「GCP派」のどちらのお客さんにも対応できるようになるんだね! クラウドエンジニアとしてはめっちゃ強い武器になりそう!
その通りです。BedrockとVertex AIの両方を比較学習すると、「Claudeをクラウドに載せる」という共通パターンと「各クラウド固有の差異」が見えてきます。マルチクラウド戦略を取る企業では、両方の知識を持つエンジニアは非常に重宝されます。
まとめ ― Bedrockは「企業がClaudeを安心して使うための器」
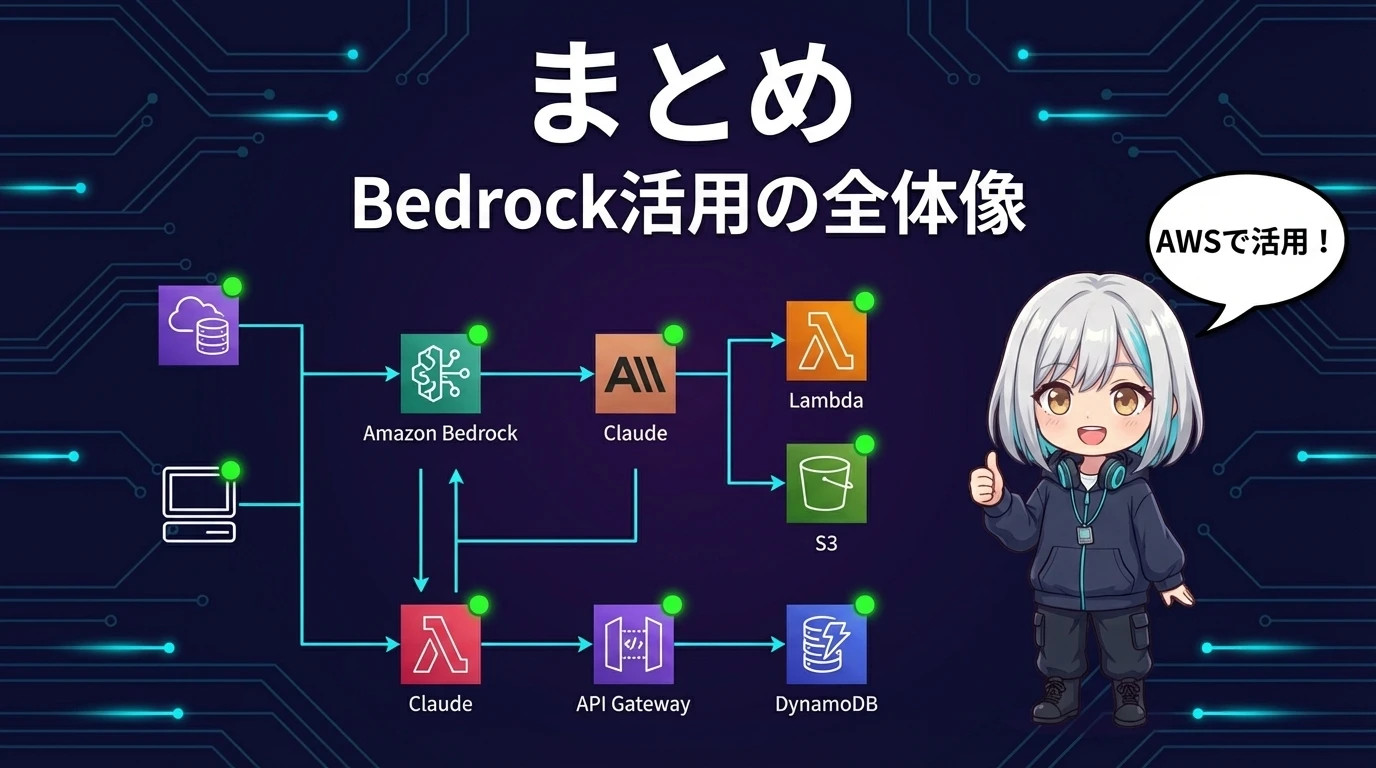
「Claude with Amazon Bedrock」コースの内容を総括します。
- Amazon Bedrockとは ― AWSのフルマネージド生成AIサービス。Claude含む複数モデルを1つのAPIから利用可能
- Bedrock経由のメリット ― IAMによるきめ細かいアクセス制御、VPC PrivateLinkによるネットワーク分離、CloudTrailによる監査ログ、AWS課金への統合、Guardrails/Knowledge Bases/Agentsなどの付加機能
- APIの違い ― 認証方式(IAMロール vs APIキー)、モデルID形式、ストリーミング方式などに差異あり。boto3でのコード例を把握しておく
- Guardrails ― AIの入出力にポリシーベースのフィルタリングを適用。コンテンツフィルタ、トピック制限、PII検出、ハルシネーション検出
- Knowledge Bases ― フルマネージドRAGで社内知識を活用。出典明示付きの回答を生成
- Agents ― Claudeに外部ツールの呼び出しとマルチステップタスク実行をさせる仕組み
- 料金 ― オンデマンド(従量課金)、Provisioned Throughput(予約)、バッチ推論(50%割引)の3パターン
- 使い分け ― 個人/PoC → 直接API、企業/本番 → Bedrock。PoCで直接API → 本番でBedrock移行が一般的
Claudeの能力を最大限に活かしつつ、企業が求めるセキュリティ・コンプライアンス・スケーラビリティを実現する――そのための「正しい載せ方」を教えてくれるのがこのコースです。AWSを使っている企業の開発者やクラウドエンジニアにとっては必修と言える内容です。

いやー、盛りだくさんだったね! IAM、Guardrails、Knowledge Bases、Agents、Provisioned Throughput……企業でClaudeを使うための「フルセット」が全部詰まったコースだ!
このコースの本質は「Claudeの使い方」ではなく「Claudeの載せ方」です。優れたAIモデルがあっても、企業のセキュリティ要件を満たせなければ本番環境には導入できない。Bedrockはその橋渡しをするサービスであり、このコースはその橋の渡り方を教えてくれます。AWSエンジニアは是非受講してください。

次はGoogle CloudのVertex AI版を紹介するよ! AWSとGCP、どっちのクラウドでClaudeを使うか迷ってる人はぜひ両方チェックしてね! じゃ、また次の記事で!