
日本語の音声合成、つまりTTS(Text-to-Speech)は、ここ数年で一気に「読み上げソフト」から「声の演技を作る道具」へ近づいてきました。昔ながらのTTSは、文章を正しく読めるか、聞き取りやすいか、機械っぽさが少ないか、という点が中心でした。ところが最近は、声色、距離感、息づかい、笑い、怒り、眠そうな読み方、電話越しのような質感まで、文章やプロンプトで指定できるモデルが出てきています。
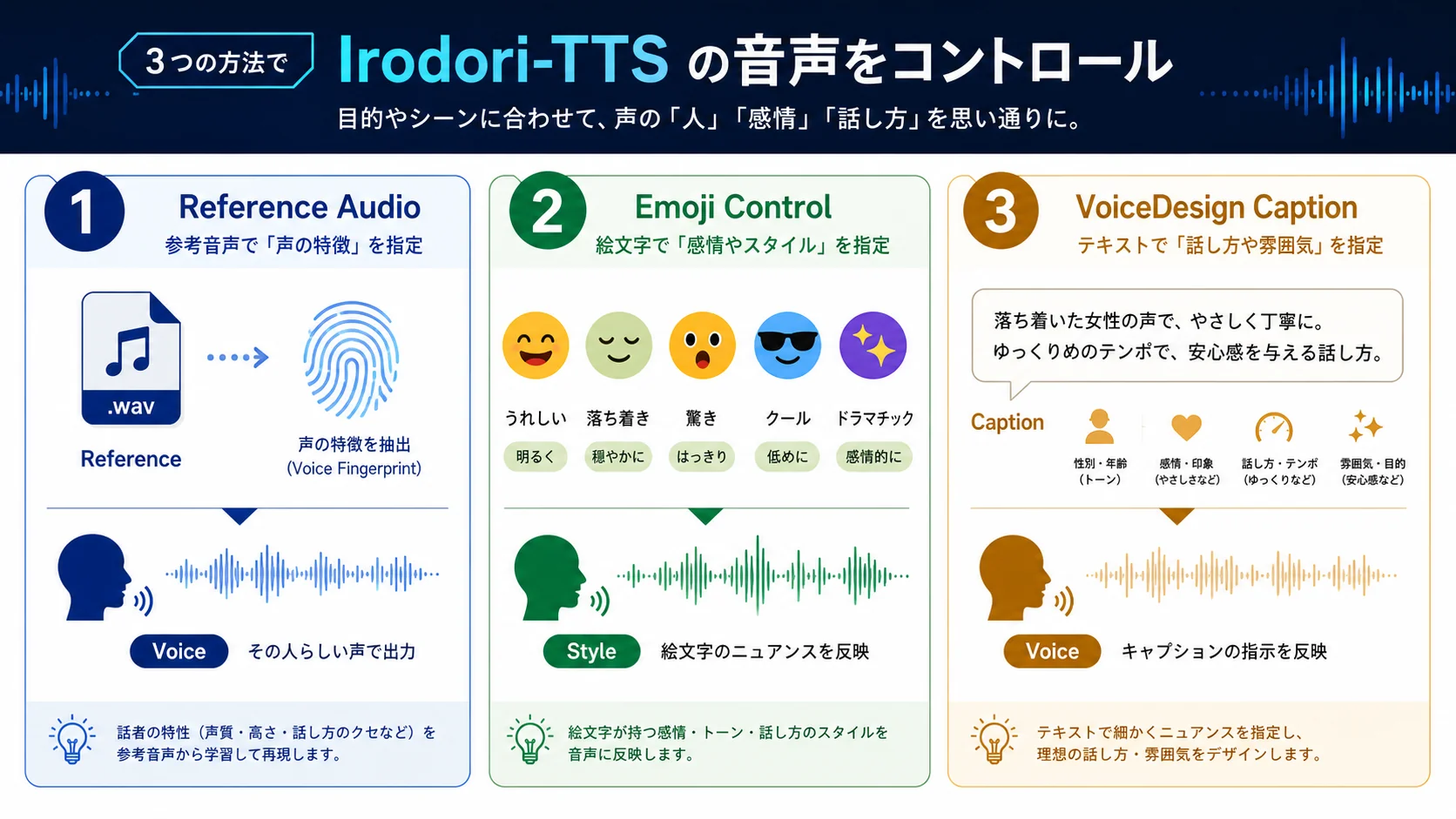
今回取り上げる Irodori-TTS は、その流れの中でもかなり面白い日本語TTSモデルです。公式のモデルカードでは、日本語向けのText-to-Speechモデルであり、Rectified Flow Diffusion Transformer、つまりRF-DiT系の構成を使うモデルとして説明されています。単に日本語を読み上げるだけではなく、参照音声を使ったゼロショット音声クローン、入力文中の絵文字による感情・話し方・効果音の制御、さらにVoiceDesign版では「低い声の女性が、苛立ちを隠せない様子で焦って話す」のような説明文だけで声の方向性を作る機能が紹介されています。
この記事では、Irodori-TTSが何なのか、どこがすごいのか、誰が作っているのか、どんな用途に向いているのか、逆にどこに注意が必要なのかを、できるだけわかりやすく整理します。専門用語も出てきますが、最初から細かい数式に入るのではなく、「なぜ制作現場で便利なのか」「どこで事故りやすいのか」という目線で見ていきます。

ねえフィア、Irodori-TTSって名前からしてかわいいけど、要するに「日本語を声にしてくれるAI」ってことで合ってる?

大きくは合っています。ただし、普通の読み上げツールとしてだけ見ると少しもったいないですね。Irodori-TTSは、日本語の文章を音声にするだけでなく、声の雰囲気や話し方まで制御しようとしているモデルです。特に、絵文字制御とVoiceDesign版が特徴的です。
まず結論:Irodori-TTSは何ができるモデルなのか
Irodori-TTSを一言で言うなら、日本語音声を生成するためのオープンなTTSモデル群です。公式GitHubには、学習と推論のコードが公開されており、Hugging Faceにはモデルウェイトやデモが用意されています。ベースモデルの Irodori-TTS-500M-v2 は、参照音声を使って声質や話し方を条件付けできる構成です。一方、Irodori-TTS-500M-v2-VoiceDesign は、参照音声なしで、声の説明文、つまりキャプションから話者の雰囲気を指定する方向に寄せた派生モデルです。
ベースモデルは「この音声の雰囲気に近い感じで、この文章を読んで」という使い方に向いています。VoiceDesign版は「落ち着いた女性の声で、近い距離感でやわらかく自然に読み上げてください」のように、声のキャラクターや感情を文章で指定する使い方に向いています。どちらも日本語入力を対象にしており、公式モデルカードではMITライセンス、Text-to-Speech、Japanese、speech、voice、ttsといったタグが付いています。
| 項目 | Irodori-TTSの特徴 |
|---|---|
| 主な用途 | 日本語テキストから音声を生成するTTS。ナレーション、キャラクターボイス試作、音声UI、研究・実験など。 |
| ベースモデル | 参照音声を使ったゼロショット音声クローン、絵文字による話し方・感情・効果音制御。 |
| VoiceDesign版 | 参照音声なしで、説明文から声の方向性を作る。声色、年齢感、性別感、感情、話し方などをキャプションで指定。 |
| 実行形態 | GitHubのコード、CLI、Gradio Web UI、Hugging Face Hub上のチェックポイントに対応。 |
| 注意点 | 日本語専用、絵文字制御やプロンプト追従は完全ではない、漢字読み精度には弱さがある、声のなりすましは禁止。 |
ここで重要なのは、Irodori-TTSが「文章を音声にする」だけではなく、声の設計を入力側でかなり細かく触れる点です。音声制作では、同じセリフでも「落ち着いて読む」「怒って読む」「近い距離でささやく」「電話越しっぽくする」「眠そうに話す」で、意味の伝わり方が大きく変わります。従来は声優、収録環境、演技指示、編集で調整していた部分の一部を、モデルへの条件指定として扱えるようにしているわけです。
開発元はどこ? 誰が作っている?
公式のGitHubリポジトリは Aratako/Irodori-TTS です。Hugging Face上のモデルも Aratako/Irodori-TTS-500M-v2 および Aratako/Irodori-TTS-500M-v2-VoiceDesign として公開されています。モデルカードの引用情報では、作者として Chihiro Arata の名前が記載されています。
GitHub READMEでは、Irodori-TTSを「Flow MatchingベースのText-to-Speechモデル」と説明し、Echo-TTSのアーキテクチャや学習設計を大きく参照していること、DACVAE系の連続潜在表現を生成ターゲットにしていることが説明されています。つまり、完全に孤立した独自方式というより、近年の音声生成研究・実装の流れを踏まえたうえで、日本語TTSとして組み上げられているプロジェクトです。
公式参照先
- GitHub: Aratako/Irodori-TTS - 学習・推論コード、CLI、Gradio UI、インストール手順、学習手順。
- Hugging Face: Irodori-TTS-500M-v2 - ベースモデルのモデルカード、機能、制限、ライセンス、倫理制限。
- Hugging Face: Irodori-TTS-500M-v2-VoiceDesign - VoiceDesign版のモデルカード、キャプション制御、サンプル、制限。
- EMOJI_ANNOTATIONS.md - 絵文字で制御できる感情・話し方・効果音の一覧。

個人開発っぽい名前だけど、GitHubとHugging Faceにちゃんとコードとモデルがあるんだね。商用サービスの黒箱APIとはちょっと違う感じ?

そうですね。少なくとも公式リポジトリでは、推論コードや学習コード、モデル構成、実行方法が確認できます。研究・実験・自分の環境での検証に向いた公開モデルとして見るのが自然です。ただし、公開されているから何をしてもよい、という意味ではありません。音声生成は権利と安全の扱いが重要です。
何がすごいのか:4つのポイント
1. 日本語TTSとして、声の表情まで扱おうとしている
第一のポイントは、日本語音声の「読み上げ」だけでなく、話し方や感情まで扱おうとしていることです。モデルカードでは、絵文字を入力文に挿入することで、話し方、感情、効果音のような要素を制御できると説明されています。たとえば、泣き声、眠そうな話し方、怒り、喜び、驚き、ため息、ささやき、電話越しのような音、早口、ゆっくり、咳、舌打ち、相槌など、音声の演出に関わる表現がEMOJI_ANNOTATIONS.mdに整理されています。
これは、台本制作の感覚に近いです。文章だけなら「こんにちは」と書くだけですが、音声制作では「明るく」「少し照れながら」「距離を近く」「疲れ気味に」「ささやくように」などの演技指示が必要になります。Irodori-TTSは、その演技指示の一部を、絵文字やキャプションという入力形式で扱おうとしているわけです。
2. 参照音声によるゼロショット音声クローンに対応している
ベースモデルのIrodori-TTS-500M-v2では、短い参照音声から話者やスタイルを条件付けするゼロショット音声クローンが特徴として挙げられています。公式の説明では、Reference Latent Encoderが参照音声由来の潜在表現をエンコードし、生成される音声の話者・スタイル条件として使われる構成です。
実務目線でいうと、これは「既存の声素材に寄せた読み上げ」を作るための入口です。もちろん、特定個人の声を無断で再現する使い方は倫理制限で明確に禁止されています。けれど、同意を得た自分の声、権利処理済みのキャラクターボイス、社内検証用の音声などを使って、ナレーションの試作やキャラクター音声の研究を行う用途には大きな可能性があります。
3. VoiceDesign版は、参照音声なしで声の方向性を文章指定できる
特に面白いのがVoiceDesign版です。公式モデルカードによると、VoiceDesign版はベースv2から派生し、参照音声用のエンコーダをキャプションエンコーダに置き換えています。つまり、声のサンプルを渡す代わりに、「若めの女性が困惑している様子で、独り言のようにささやく」「低めの女性の声で、嫌悪感を示しながら怒っている」のような説明文を渡して、声の雰囲気を作る方向です。
これは制作フローをかなり変えます。参照音声を用意しなくても、まずはキャラクターの声の方向性をテキストで試せるからです。たとえば、ゲームの仮ボイス、動画ナレーションの雰囲気確認、キャラクター設定の音声イメージ作り、ボイスドラマのラフ検証などで、「このキャラは落ち着いた声がいいのか、少し高めで元気な声がいいのか」を試す段階に使いやすくなります。
4. ローカル実行・CLI・Gradio UIまで用意されている
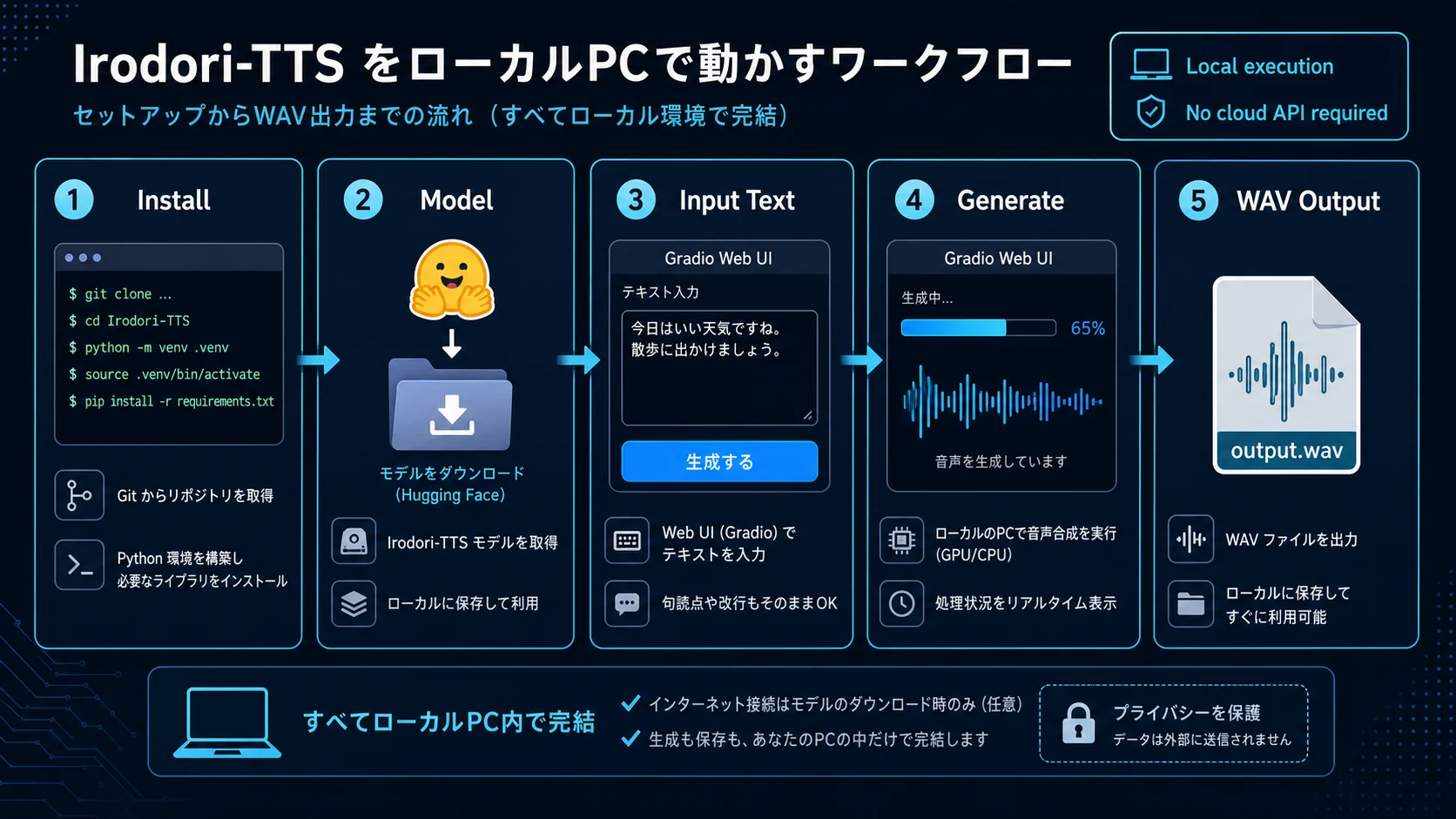
GitHub READMEには、uv syncによる環境構築、infer.pyによるCLI推論、gradio_app.pyによるWeb UI、VoiceDesign用のgradio_app_voicedesign.pyが紹介されています。Hugging Face Hubのチェックポイントを指定して実行できるため、モデルファイルを手動で細かく管理しなくても始めやすい構成です。
商用クラウドAPIだけで完結するTTSと違い、ローカル環境で試せることには大きな意味があります。研究用途では推論条件を変えやすく、制作用途では台本の試作を自分のPC内で回しやすい。もちろんGPUや環境構築の知識は必要ですが、APIの利用制限や外部送信を避けたいワークフローでは魅力があります。
内部の仕組みをざっくり理解する
ここから少しだけ技術寄りに見ていきます。Irodori-TTSの公式説明には、RF-DiT、DACVAE、Text Encoder、Reference Latent Encoder、Caption Encoder、Diffusion Transformer、Low-Rank AdaLN、RoPE、SwiGLUなど、専門用語がたくさん出てきます。全部を一度に理解しようとすると大変ですが、記事として押さえるべき流れは比較的シンプルです。
まず、TTSモデルは入力されたテキストをそのまま波形に変換しているわけではありません。テキストをモデルが扱いやすい表現に変換し、音声をモデルが扱いやすい潜在表現として生成し、それを最後に波形へ戻します。Irodori-TTS v2では、音声表現として Semantic-DACVAE-Japanese-32dim という32次元のコーデックを使い、48kHz波形再構成に対応することが説明されています。
ベースモデルでは、テキストエンコーダが読み上げる文章を理解し、参照音声由来のエンコーダが話者・スタイルの条件を作り、Diffusion Transformerが音声の潜在表現を生成します。VoiceDesign版では、参照音声の代わりにキャプションエンコーダが「声の説明文」を読み込み、それを条件として使います。つまり、ベースモデルは「音声サンプルに寄せる」、VoiceDesign版は「文章の説明に寄せる」という違いがあります。

うーん、つまり「文章」と「声のヒント」をモデルに渡して、いったん音声の設計図みたいなものを作って、それを波形に戻すって感じ?

かなり良い理解です。厳密には「音声の設計図」という言い方は比喩ですが、記事の読者向けにはその説明で十分です。Irodori-TTSは波形を直接一文字ずつ組み立てるのではなく、テキスト条件や声の条件をもとに、音声の潜在表現を生成してから波形へ戻すタイプだと捉えるとわかりやすいです。
ベースモデルとVoiceDesign版の違い
Irodori-TTSを理解するうえで、ベースモデルとVoiceDesign版の違いは重要です。名前が似ているので混同しやすいのですが、使い方の発想が違います。
| モデル | 主な入力 | 向いている用途 | 注意点 |
|---|---|---|---|
| Irodori-TTS-500M-v2 | 読み上げテキスト、必要に応じて参照音声、絵文字制御 | 参照音声の雰囲気に寄せた音声生成、話者・スタイル条件付きのTTS | 参照音声の権利と同意が重要。特定個人の無断再現は禁止。 |
| Irodori-TTS-500M-v2-VoiceDesign | 読み上げテキスト、声・感情・話し方を説明するキャプション、絵文字制御 | 参照音声なしで声の方向性を試す、キャラクター声のラフ設計、ナレーション案の比較 | 複雑すぎる、矛盾したキャプションでは不安定になりうる。プロンプト追従は完全ではない。 |
ベースモデルは、参照音声を使えるぶん、具体的な声の方向に寄せやすい一方で、権利・同意の管理が重くなります。VoiceDesign版は、参照音声を使わずに声を設計できるため、初期検討や試作には扱いやすいです。ただし、説明文だけで完璧に狙い通りの声が出るとは限りません。公式の制限にも、プロンプト追従や絵文字制御の効果は文脈によって変わり、常に完全ではないことが示されています。
絵文字制御は何が面白いのか
Irodori-TTSのわかりやすい特徴が、絵文字制御です。公式のEMOJI_ANNOTATIONS.mdでは、入力文に特定の絵文字を挿入することで、話し方、感情、効果音を制御できると説明されています。同じ絵文字を複数回使うと効果を強調できることも示されています。
これは、プロンプトだけで「怒って」「泣いて」「早口で」と書くのとは少し違います。台本の中に演技記号を混ぜるような感覚です。たとえば、文章の途中で笑いを入れる、眠そうな雰囲気にする、息をのむ、ゆっくり読む、電話越しっぽくする、といった指定を、テキストの流れの中に配置できます。うまく使えば、単調な読み上げではなく、場面に合わせた演技に近づけられます。
ただし、ここにも注意があります。絵文字制御は便利ですが、公式にも「完全ではない」と説明されています。TTSモデルは、入力記号を機械的にオンオフのスイッチとして扱うわけではありません。前後の文脈、文章の長さ、声の条件、乱数、モデルの得意不得意によって出方が変わります。制作で使うなら、絵文字は「演技の方向を伝える補助」と考え、必ず複数候補を生成して耳で確認するのが現実的です。

文章の中に絵文字を入れたら、声が笑ったり、眠そうになったりするの、かなり直感的だね。台本に演技メモを入れる感じ!

そうです。とても直感的です。ただし、演技記号は万能ではありません。最終的には生成結果を聞き比べて、必要なら台本、絵文字、キャプションを調整する工程が必要です。
実際にはどう使う? 制作ワークフローの例
たとえば、短い解説動画のナレーションを作る場合を考えてみます。まず台本を書きます。次に、通常読み上げでラフ音声を作ります。声の方向性が必要なら、VoiceDesign版で「落ち着いた中性的な声」「少し早口でテンポよく」「近い距離感でやさしく」といったキャプションを試します。さらに、場面ごとに絵文字制御を入れて、笑い、驚き、ため息、間などを調整します。最後に、複数候補を聞き比べて、動画の尺やBGMに合うものを採用します。
ゲームやノベルの仮ボイスにも向いています。本収録前に、キャラクターAは少し低めで落ち着いた声、キャラクターBは高めで早口、キャラクターCは眠そうで間が多い、という方向性を試せます。仮ボイスがあるだけで、シナリオのテンポ、セリフの長さ、掛け合いの間、感情の流れが確認しやすくなります。
音声UIやアプリのプロトタイプでも便利です。たとえば、通知音声、案内音声、チュートリアル、アラート、エラー説明などは、読み上げの正確性だけでなく、ユーザーに与える印象が重要です。「落ち着いて案内する」「急ぎすぎない」「不安を煽らない」「少し親しみやすい」などの方向性を、VoiceDesignや絵文字制御で試せます。
インストールと実行のイメージ
公式READMEでは、GitHubからリポジトリをクローンし、uv syncで依存関係を入れ、infer.pyでCLI推論する流れが示されています。ベースモデルなら、Hugging FaceのチェックポイントID、読み上げテキスト、参照音声、出力wavを指定します。参照音声なしで実行するオプションもあります。VoiceDesign版では、チェックポイントIDにVoiceDesignモデルを指定し、キャプションと--no-refを使って出力します。
また、Gradio Web UIも用意されています。通常版はgradio_app.py、VoiceDesign版はgradio_app_voicedesign.pyです。コマンドラインに慣れていない場合でも、ローカルのWeb画面からテキストや条件を入力して試せるのは大きいです。Hugging Face Space上のデモも用意されていますが、本格的に試すならローカル実行の方が条件を細かく管理しやすいでしょう。
ざっくりした実行イメージ
- GitHubからIrodori-TTSを取得する。
uv syncで必要なPython環境を整える。- Hugging Faceのチェックポイントを指定する。
- 読み上げたい日本語テキストを渡す。
- ベースモデルなら参照音声、VoiceDesign版ならキャプションを渡す。
- wavファイルとして出力し、聞き比べる。
この記事は使い方の概念説明です。実際の導入時は、公式READMEの最新版を確認してください。
弱点と制限:ここを理解しておくと失敗しにくい
Irodori-TTSは面白いモデルですが、万能ではありません。公式モデルカードでも、いくつかの制限が明記されています。まず、日本語入力専用です。英語や多言語TTSとして使うモデルではありません。日本語コンテンツ制作に向いたモデルとして捉えるべきです。
次に、漢字読みの精度には注意が必要です。公式の制限では、同規模の他TTSモデルと比べて、漢字を正確に読む能力が相対的に弱いこと、必要に応じて複雑な漢字をひらがな・カタカナへ変換するとよいことが説明されています。これは実務ではかなり大事です。人名、専門用語、固有名詞、難読語、当て字、地名などは、台本側で読みを明示した方が安全です。
また、絵文字制御やVoiceDesignのキャプション追従も完全ではありません。たとえば、「低い声で、でも高く、怒っているけど穏やかに、早口だけどゆっくり」のように矛盾した指示を出すと、結果が不安定になりやすいです。複雑すぎるキャプションも、モデルがどの要素を優先するか読みづらくなります。制作では、一度に多くを指定するより、声質、距離感、感情、速度のように、重要な要素を絞って試す方が安定します。
| 制限 | 実務での対策 |
|---|---|
| 日本語専用 | 日本語台本に使う。多言語案件では別モデルを検討する。 |
| 漢字読みが不安定な場合がある | 難読語、固有名詞、人名、地名はひらがな・カタカナで読みを補う。 |
| 絵文字制御は完全ではない | 絵文字を演技補助として使い、複数候補を生成して確認する。 |
| 複雑・矛盾したキャプションに弱い | キャプションは短く、優先順位をはっきりさせる。 |
| 参照音声利用には権利リスクがある | 本人同意、利用許諾、公開範囲、クレジット、禁止用途を確認する。 |

漢字読みは要注意なんだ。たしかに、人名とか地名ってAI読み上げで変になりやすいよね。

はい。TTSを実制作で使うときは、モデルの性能だけでなく、台本の整え方が品質を左右します。難しい漢字は読みを開く、数字や記号は読み上げたい形に書き直す、固有名詞は必ず確認する。この前処理がとても重要です。
安全・権利面:音声生成で一番気をつけたいこと

Irodori-TTSのモデルカードには、ライセンスとは別に倫理制限が明記されています。特に重要なのは、特定の実在人物、声優、著名人、公人などの声を、本人の明示的な同意なしにクローンまたはなりすまし目的で使ってはいけないことです。また、誤解を招く合成音声、ディープフェイク、 misinformation、つまり他人を欺く目的の音声生成も禁止されています。
これはIrodori-TTSに限らず、音声生成AI全般で非常に重要です。音声は、画像や文章よりも「本人らしさ」と結びつきやすいメディアです。似た声で何かを言わせると、聞いた人は本人の発言だと誤解しやすい。だからこそ、参照音声を使う場合は、素材の権利、本人の同意、用途、公開範囲を必ず確認する必要があります。
安全に使うなら、まずは自分の声、許諾済みの音声、権利処理されたキャラクター音声、研究用の適切なデータに限定するのが基本です。公開コンテンツでは、AI生成音声であることを必要に応じて明示し、誰かの実在の声だと誤解される表現を避けるべきです。特にSNS投稿、広告、政治・医療・金融・ニュース系の文脈では、合成音声の扱いは慎重にしなければいけません。
安全に使うための最低ライン
- 他人の声を無断でクローンしない。
- 実在人物が言っていないことを、本人の発言のように聞かせない。
- AI生成音声であることを隠して誤認させない。
- 参照音声の出所、権利、同意、利用範囲を記録する。
- 商用利用や公開前には、モデルカードとライセンス、各国の法令、プラットフォーム規約を確認する。
どんな人に向いている?
Irodori-TTSは、一般ユーザーが何も考えずにワンクリックで大量音声を作るツールというより、音声制作やAI実験に慣れた人が「日本語の声を細かく試す」ためのモデルに近いです。特に向いているのは、動画制作者、ゲーム開発者、ノベル制作者、研究者、音声UIのプロトタイパー、AI音声ワークフローを自分で組みたいエンジニアです。
動画制作者なら、台本の読み上げ、仮ナレーション、ショート動画用の声の方向性確認に使えます。ゲームやノベルなら、キャラクターごとの声質ラフ、セリフの長さ確認、イベントシーンのテンポ確認に使えます。研究者や開発者なら、Flow Matching TTS、DACVAE latent、キャプション条件付け、絵文字アノテーションの実験対象として面白いでしょう。
一方で、商用ナレーションを高い安定性で大量生産したいだけなら、商用TTSサービスの方が楽な場面もあります。Irodori-TTSはオープンで自由度が高い反面、環境構築、GPU、読み調整、権利確認、品質チェックを自分で行う必要があります。自由度と手間はセットです。

なるほど。ボタン押すだけのサービスというより、「自分の音声制作ワークフローに組み込める素材」って感じなんだね。

その理解が近いです。Irodori-TTSは、完成品サービスというより、音声生成の実験・制作・研究に使える公開モデルとして魅力があります。だからこそ、使いこなすにはモデルの強みと弱みの両方を理解する必要があります。
他のTTSと比べたときの見どころ
一般的なTTSサービスは、使いやすさ、安定性、商用サポート、多言語対応、API連携などが強みです。Irodori-TTSはその方向とは少し違い、ローカルで動かせる公開モデルとして、声の制御や研究・試作の自由度が魅力です。特に、絵文字制御とVoiceDesignの組み合わせは、音声演出の試作に向いています。
商用サービスでは、選べる話者や感情スタイルがあらかじめ決まっていることが多いです。Irodori-TTS VoiceDesignは、キャプションで声の方向性を説明できるため、固定プリセットの間を探るような使い方ができます。たとえば「若い女性」「低い声の女性」「やや高めの男性」「申し訳なさそう」「苛立ちを隠せない」「囁くように」といった粒度で、声のニュアンスを探索できます。
ただし、探索できることと、必ず狙い通りに出ることは別です。モデルカードにもある通り、プロンプト追従や絵文字制御は不完全です。したがって、制作で使うなら「一発で完成音声を作る」よりも、「候補を複数作って選ぶ」「台本とキャプションを調整する」「必要なら人間の声や別ツールと併用する」前提で考える方が現実的です。
実用時のプロンプト設計:短く、矛盾なく、優先順位を明確に
VoiceDesign版を使うときは、キャプションの書き方が結果を左右します。長く書けば書くほど良いわけではありません。むしろ、声質、話者属性、感情、距離感、速度、音質のうち、何を一番大事にしたいのかを短くまとめた方が扱いやすいです。
たとえば、以下のような書き方が考えられます。
- 「落ち着いた女性の声で、近い距離感で、やわらかく自然に話す」
- 「若めの男性の声で、少し緊張しながら、申し訳なさそうに話す」
- 「低めの女性の声で、静かに怒りを抑えながら、ゆっくり話す」
- 「明るい中性的な声で、テンポよく、親しみやすく説明する」
逆に、「低い声だけど高く、怒っているけど穏やかで、早口だけどゆっくり、遠い距離だけど耳元で」のように矛盾が多い指定は避けた方がよいです。生成AIのプロンプト全般と同じで、曖昧な願望を詰め込むより、優先順位を絞る方が成功しやすくなります。
記事・動画・ゲームでの使い分け
記事制作で使う場合、Irodori-TTSは「本文そのものを読ませる」よりも、要約音声、導入音声、キャラクターコメント、SNS用短尺音声に向いています。長文記事をそのまま読み上げると、漢字読みやテンポの調整が大変になるため、音声用の短い台本を別に作る方が安定します。
動画制作では、ナレーションのラフ、キャラクターの掛け合い、ショート動画のセリフ案、BGMとの尺合わせに使えます。特に、VoiceDesignで複数の声を試し、絵文字で話し方を少し変え、候補を聞き比べる流れは相性が良いです。
ゲーム制作では、仮ボイスがあるだけでシナリオの手触りが変わります。セリフが長すぎないか、感情の切り替えが唐突ではないか、掛け合いの間が成立しているかを、実際の音声に近い形で確認できます。本番収録の前に台本を磨く工程として使うと効果的です。
まとめ:Irodori-TTSは「声を作る操作感」を日本語TTSに持ち込むモデル
Irodori-TTSの面白さは、単に日本語を読み上げることではありません。参照音声、絵文字、VoiceDesignキャプションという複数の条件指定を通じて、声の雰囲気や話し方を作ろうとしている点にあります。音声生成AIが「文章を読む機械」から「演技を試す制作ツール」へ近づいていることを感じられるモデルです。
一方で、実制作に使うなら、弱点も理解する必要があります。日本語専用であること、漢字読みが不安定な場合があること、絵文字制御やキャプション追従が完全ではないこと、そして何より音声の権利と同意が重要であること。これらを無視すると、技術的には面白くても、制作物としては危険になります。
安全に、かつ実用的に使うなら、まずはVoiceDesign版で参照音声なしの声の方向性を試し、台本を音声向けに整え、必要に応じて絵文字で演技を加え、複数候補を聞き比べるのがよさそうです。参照音声を使う場合は、本人同意と利用許諾を必ず確認する。公開時にはAI生成音声であることを必要に応じて明示する。ここまで含めて、音声生成AIのワークフローです。

Irodori-TTS、思ったよりちゃんと「制作ツール」って感じだった! ただ読み上げるだけじゃなくて、声の方向性を探すのに使えるのが面白いね。
はい。Irodori-TTSは、声の試作、演技の探索、日本語TTS研究にとても興味深いモデルです。ただし、音声は人の人格や信用に強く結びつくメディアです。便利さと同じくらい、同意、権利、表示、安全性を大切に扱う必要があります。
公式・参考リンク
- GitHub: Aratako/Irodori-TTS - Irodori-TTSの学習・推論コード、インストール、CLI、Gradio UI、ライセンス情報。
- Hugging Face: Irodori-TTS-500M-v2 - ベースモデルの機能、v2改善点、構成、制限、倫理制限。
- Hugging Face: Irodori-TTS-500M-v2-VoiceDesign - VoiceDesign版のキャプション制御、サンプル、制限、倫理制限。
- EMOJI_ANNOTATIONS.md - 絵文字による話し方・感情・効果音制御の一覧。
- Semantic-DACVAE-Japanese-32dim - Irodori-TTS v2で利用される日本語音声向けコーデック。
- Echo-TTS - Irodori-TTSのREADMEでアーキテクチャ・学習設計の参照元として挙げられているTTSプロジェクト。